Kilian Q. Weinberger, Yoav Artzi, Jennifer J. Sun
Department of Computer Science, Cornell University
LLMs entangle language and factual knowledge, making it difficult to inspect, update, or forget specific facts. LMLM introduces a new class of models that externalize factual knowledge into a database and learn during pretraining when and how to retrieve facts instead of memorizing them.
📄 [ArXiv] 💻 [Github] 🎤 [Talk by Kilian @ Simons Institute, UC Berkeley]
Traditional LLMs tightly couple linguistic ability with memorized factual knowledge. This:
- Requires repeated exposure to facts during training
- Makes updates and unlearning difficult
- Wastes parameter capacity on rare, specific knowledge
LMLM changes this by treating knowledge differently:
- Common knowledge (generalizable) is retained in model weights
- Specific knowledge (e.g., birthdates, locations) is offloaded to an external database
The model learns when and how to retrieve facts from an externalized database, aiming to decouple the memorization of specific knowledge from its weights—making it easier to inspect, verify, and update factual information.
LMLM integrates factual lookups directly into pretraining and inference:
We annotate the pretraining corpus with database lookup calls using a lightweight, fine-tuned Annotator model. This annotates factual content for externalization.
Factual tokens returned from the database are masked from the loss, preventing the model from memorizing them and encouraging reliance on retrieval.
During inference, LMLM interleaves text generation with factual retrieval, enabling verifiable outputs.
We compare LMLM models to standard LLMs of the same size, trained on the same data but without external memory. LMLM offers three key advantages:
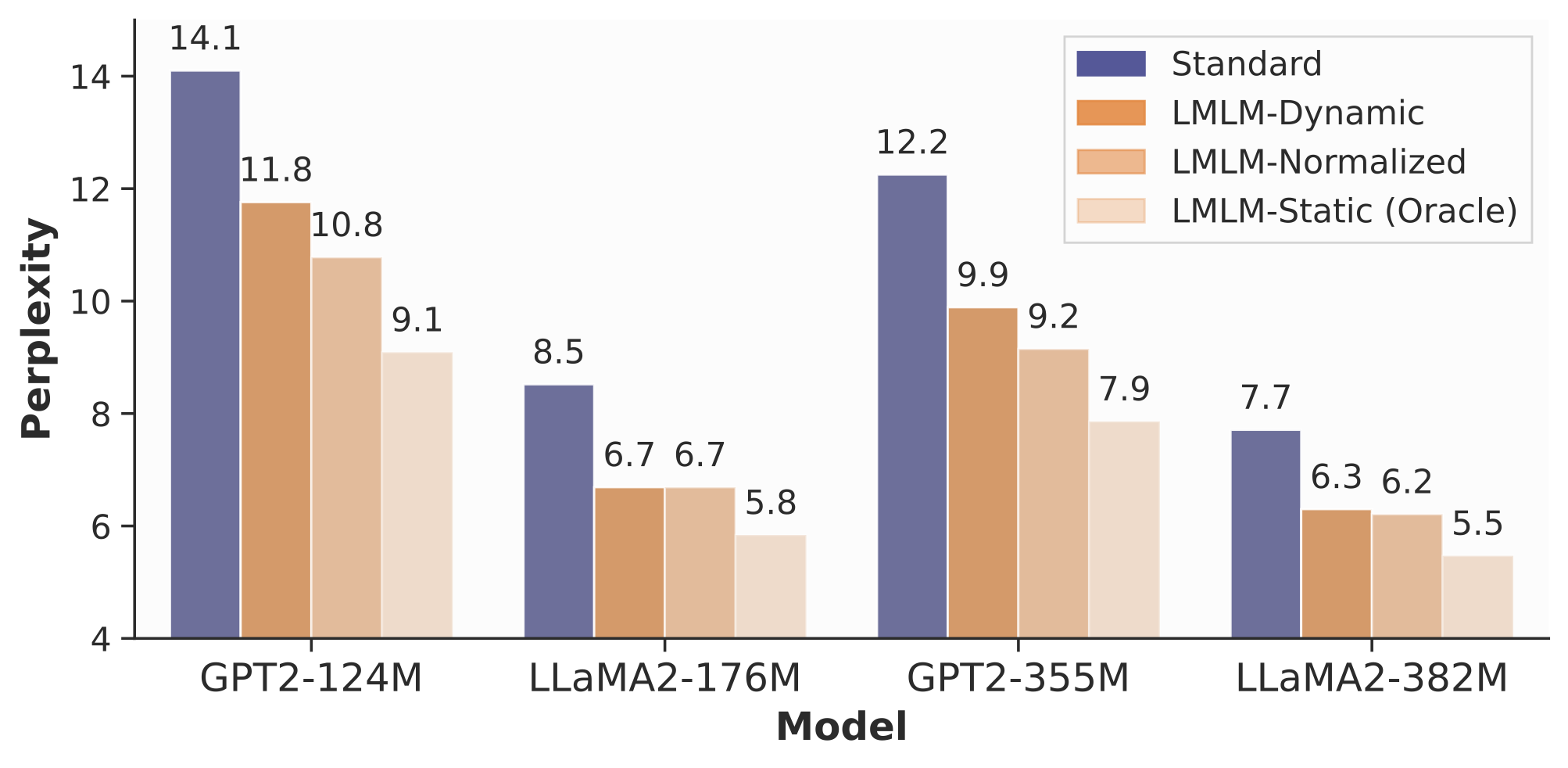
Learning to look up facts is easier than memorizing them
LMLM achieves lower perplexity, indicating that offloading factual knowledge improves training efficiency.
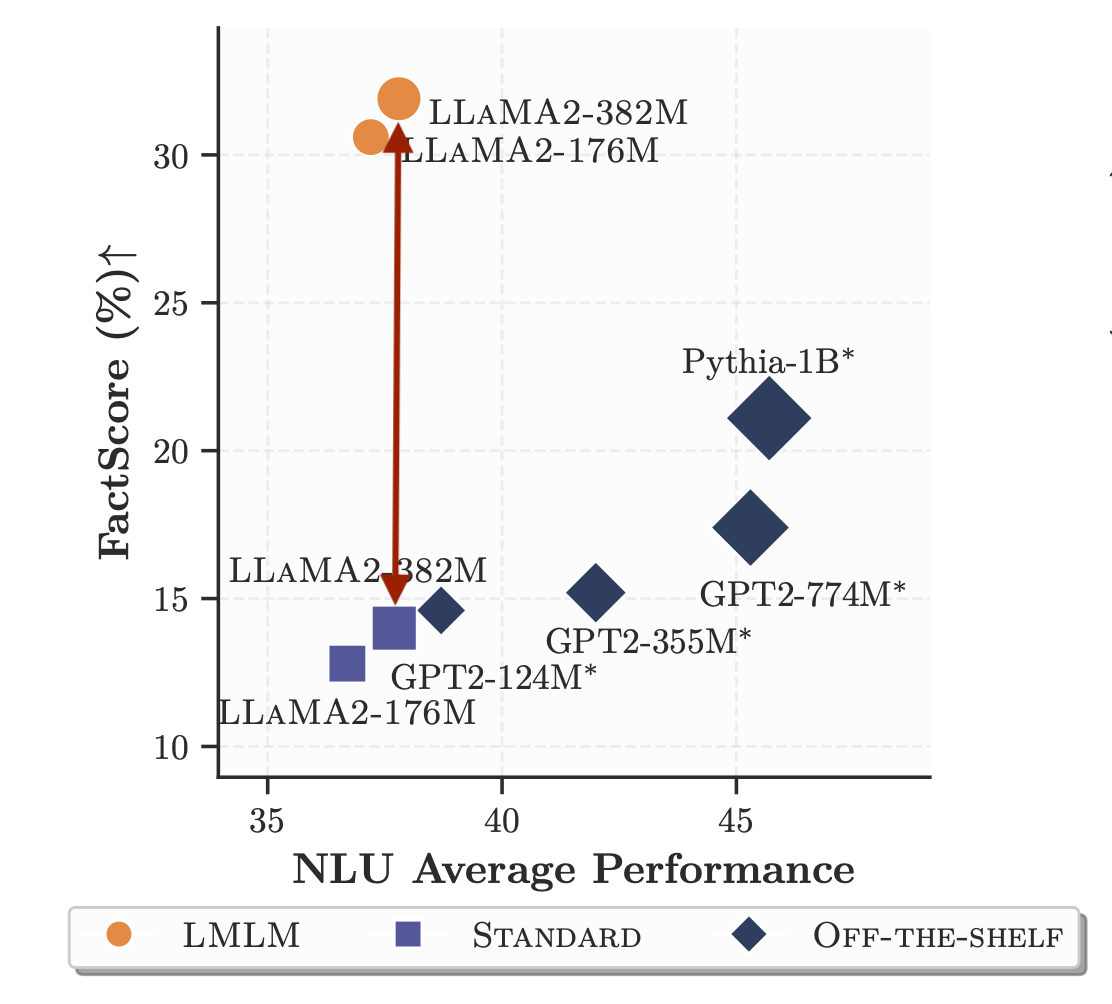
Externalizing knowledge improves factual precision
Even small LMLMs outperform much larger LLMs on factual precision benchmarks like FactScore and T-REx, without sacrificing NLU performance.
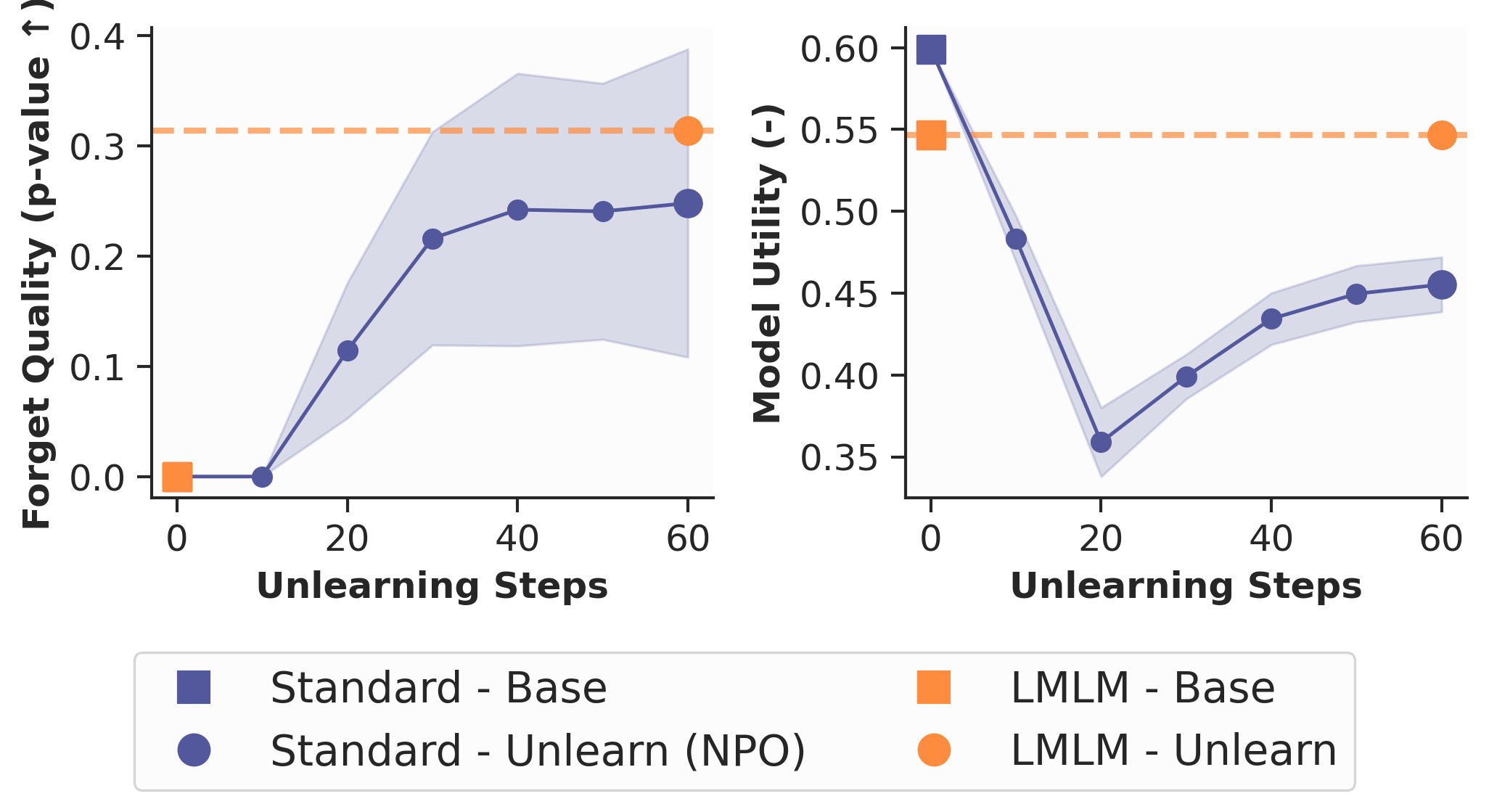
Enables instant unlearning by design
Because knowledge is stored externally, editing or unlearning facts becomes as simple as removing entries from the database. On the TOFU benchmark, LMLM achieves reliable forgetting without degrading overall model performance.
LMLM externalizes factual knowledge by design, allowing direct control over what the model knows and forgets. We support this with two findings:
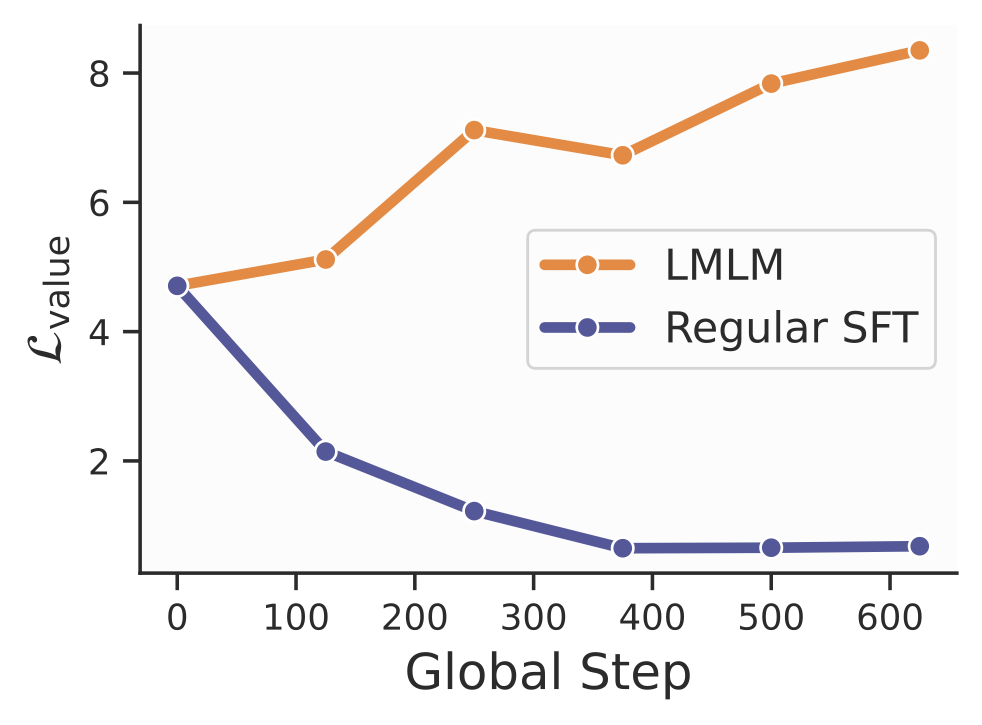
High loss on masked factual tokens
When factual tokens are masked during training, LMLM maintains high loss on these tokens—indicating that it does not store them internally.
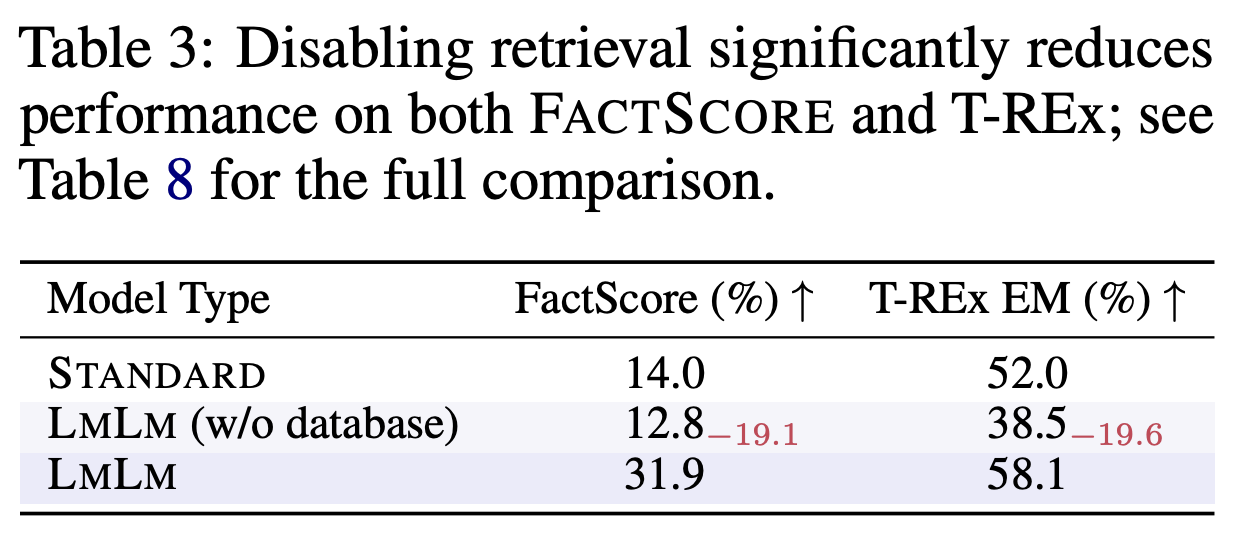
Performance drop without database access
Disabling the external database during inference causes a significant drop in factual precision, suggesting that LMLM retrieves rather than memorizes facts.
While our current experiments are limited in scale, the results highlight a promising direction: LMLMs can reduce reliance on large parameter counts for factual accuracy. This approach opens the door to integrating external memory with techniques from knowledge representation, editing, symbolic reasoning, and interpretability. By enabling real-time, verifiable knowledge updates, LMLMs offer a compelling new paradigm for how language models store, access, and maintain knowledge.